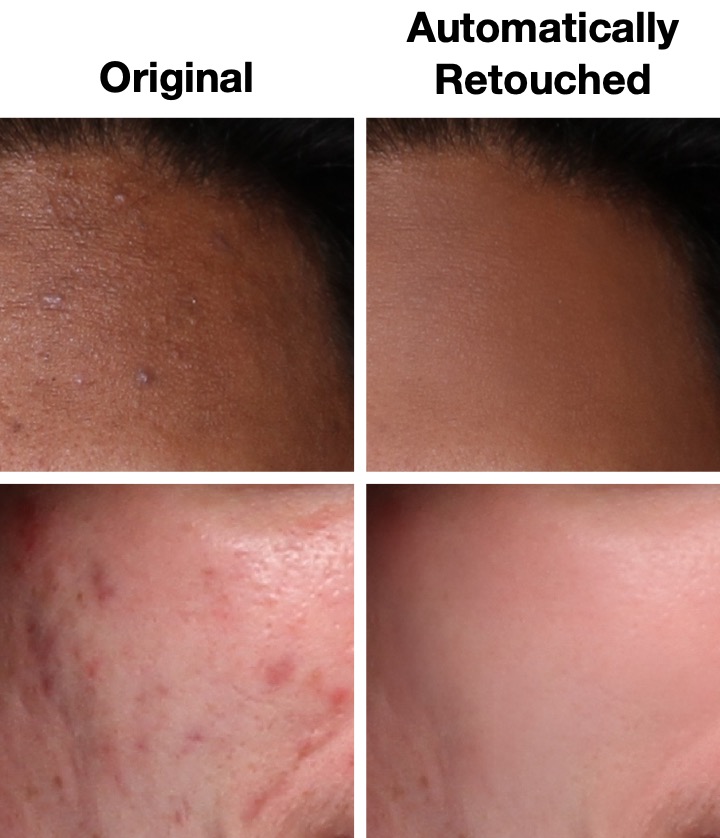
Face retouching is one of the most time-consuming steps in professional photography pipelines. The existing automated approaches blindly apply smoothing on the skin, destroying the delicate texture of the face. We present the first automatic face retouching approach that produces high-quality professional-grade results in less than two seconds. Unlike previous work, we show that our method preserves textures and distinctive features while retouching the skin. We demonstrate that our trained models generalize across datasets and are suitable for low-resolution cellphone images. Finally, we release the first large-scale, professionally retouched dataset with our baseline to encourage further work on the presented problem.
@inproceedings{Shafaei21,author={Shafaei, Alireza and Schmidt, Mark and Little, James J.},title={AutoRetouch: Automatic Professional Face Retouching},booktitle={WACV},year={2021},website={https://openaccess.thecvf.com/content/WACV2021/html/Shafaei_AutoRetouch_Automatic_Professional_Face_Retouching_WACV_2021_paper.html},pdf={https://openaccess.thecvf.com/content/WACV2021/papers/Shafaei_AutoRetouch_Automatic_Professional_Face_Retouching_WACV_2021_paper.pdf},dataset={https://github.com/skylab-tech/ffhqr-dataset},dataset_name={FFHQR},selected={true},image={papers/autoretouch.jpg},youtube={https://www.youtube.com/watch?v=NBFkSL5XhHA},notes={Oral Presentation},news={https://www.cs.ubc.ca/news/2021/02/cs-alumnus-success-story-creating-picture-perfect-business-machine-learning},news_title={UBC CS},bibtex_show={true}}
2020
Shafaei, A. (2020). Pragmatic Investigations of Applied Deep Learning in Computer Vision Applications. Ph.D. Dissertation, University of British Columbia.
Deep neural networks have dominated performance benchmarks on numerous machine learning tasks. These models now power the core technology of a growing list of products such as Google Search, Google Translate, Apple Siri, and even Snapchat, to mention a few. We first address two challenges in the real-world applications of deep neural networks in computer vision: data scarcity and prediction reliability. We present a new approach to data collection through synthetic data via video games that is cost-effective and can produce high-quality labelled training data on a large scale. We validate the effectiveness of synthetic data on multiple problems through cross-dataset evaluation and simple adaptive techniques. We also examine the reliability of neural network predictions in computer vision problems and show that these models are fragile on out-of-distribution test data. Motivated by statistical learning theory, we argue that it is necessary to detect out-of-distribution samples before relying on the predictions. To facilitate the development of reliable out-of-distribution sample detectors, we present a less biased evaluation framework. Using our framework, we thoroughly evaluate over ten methods from data mining, deep learning, and Bayesian methods. We show that on real-world problems, none of the evaluated methods can reliably certify a prediction. Finally, we explore the applications of deep neural networks on high-resolution portrait production pipelines. We introduce AutoPortrait, a pipeline that performs professional-grade colour-correction, portrait cropping, and portrait retouching in under two seconds. We release the first large scale professional retouching dataset.
@thesis{Shafaei2016,author={Shafaei, Alireza},title={Pragmatic Investigations of Applied Deep Learning in Computer Vision Applications},school={Ph.D. Dissertation, University of British Columbia},year={2020},pdf={https://open.library.ubc.ca/media/download/pdf/24/1.0395340/3},image={papers/phd.jpg},bibtex_show={true}}
2019
A Less Biased Evaluation of Out-of-distribution Sample Detectors
(Spotlight)
In the real world, a learning system could receive an input that is unlike anything it has seen during training. Unfortunately, out-of-distribution samples can lead to unpredictable behaviour. We need to know whether any given input belongs to the population distribution of the training/evaluation data to prevent unpredictable behaviour in deployed systems. A recent surge of interest in this problem has led to the development of sophisticated techniques in the deep learning literature. However, due to the absence of a standard problem definition or an exhaustive evaluation, it is not evident if we can rely on these methods. What makes this problem different from a typical supervised learning setting is that the distribution of outliers used in training may not be the same as the distribution of outliers encountered in the application. Classical approaches that learn inliers vs. outliers with only two datasets can yield optimistic results. We introduce OD-test, a three-dataset evaluation scheme as a more reliable strategy to assess progress on this problem. We present an exhaustive evaluation of a broad set of methods from related areas on image classification tasks. Contrary to the existing results, we show that for realistic applications of high-dimensional images the previous techniques have low accuracy and are not reliable in practice.
@inproceedings{Shafaei19,author={Shafaei, Alireza and Schmidt, Mark and Little, James J.},title={A Less Biased Evaluation of Out-of-distribution Sample Detectors},booktitle={BMVC},year={2019},pdf={https://arxiv.org/pdf/1809.04729.pdf},code={https://github.com/ashafaei/OD-test},arxiv={1809.04729},selected={true},image={papers/odtest.jpg},poster={poster/bmvc19_poster.pdf},notes={Spotlight},bibtex_show={true}}
2018
MASAGA: A Linearly-Convergent Stochastic First-Order Method for Optimization on Manifolds
@article{babanezhadmasaga,title={MASAGA: A Linearly-Convergent Stochastic First-Order Method for Optimization on Manifolds},author={Babanezhad, Reza and Laradji, Issam H. and Shafaei, Alireza and Schmidt, Mark},journal={ECML},year={2018},code={https://github.com/IssamLaradji/MASAGA},pdf={www.ecmlpkdd2018.org/wp-content/uploads/2018/09/617.pdf},image={papers/masaga.png},bibtex_show={true}}
Patent: Machine learning systems and methods for document matching (US Patent App. 15/903,344)
Holtham, Elliot Mark,
Shafaei, Alireza,
and Granek, Justin
2018.
2016
Play and Learn: Using Video Games to Train Computer Vision Models
Video games are a compelling source of annotated data as they can readily provide fine-grained groundtruth for diverse tasks.
However, it is not clear whether the synthetically generated data has enough resemblance to the real-world images to improve the performance of computer vision models in practice.
We present experiments assessing the effectiveness on real-world data of systems trained on synthetic RGB images that are extracted from a video game.
We collected over 60,000 synthetic samples from a modern video game with similar conditions to the real-world CamVid and Cityscapes datasets.
We provide several experiments to demonstrate that the synthetically generated RGB images can be used to improve the performance of deep neural networks on both image segmentation and depth estimation.
These results show that a convolutional network trained on synthetic data achieves a similar test error to a network that is trained on real-world data for dense image classification.
Furthermore, the synthetically generated RGB images can provide similar or better results compared to the real-world datasets if a simple domain adaptation technique is applied.
Our results suggest that collaboration with game developers for an accessible interface to gather data is potentially a fruitful direction for future work in computer vision.
@inproceedings{Shafaei16b,author={Shafaei, Alireza and Little, James J. and Schmidt, Mark},title={Play and Learn: Using Video Games to Train Computer Vision Models},booktitle={BMVC},year={2016},pdf={https://arxiv.org/pdf/1608.01745.pdf},arxiv={1608.01745},image={papers/bmvc16_1.png},poster={poster/bmvc16_poster.pdf},news={https://www.technologyreview.com/s/602317/self-driving-cars-can-learn-a-lot-by-playing-grand-theft-auto/},news_title={MIT Technology Review},bibtex_show={true}}
Real-Time Human Motion Capture with Multiple Depth Cameras
(Oral Presentation)
Commonly used human motion capture systems require intrusive attachment of markers that are visually tracked with multiple cameras. In this work we present an efficient and inexpensive solution to markerless motion capture using only a few Kinect sensors. Unlike the previous work on 3d pose estimation using a single depth camera, we relax constraints on the camera location and do not assume a co-operative user. We apply recent image segmentation techniques to depth images and use curriculum learning to train our system on purely synthetic data. Our method accurately localizes body parts without requiring an explicit shape model. The body joint locations are then recovered by combining evidence from multiple views in real-time. We also introduce a dataset of ~6 million synthetic depth frames for pose estimation from multiple cameras and exceed state-of-the-art results on the Berkeley MHAD dataset.
@inproceedings{Shafaei16,author={Shafaei, Alireza and Little, James J.},title={Real-Time Human Motion Capture with Multiple Depth Cameras},booktitle={CRV},year={2016},organization={Canadian Image Processing and Pattern Recognition Society (CIPPRS)},url={http://www.cs.ubc.ca/~shafaei/homepage/projects/crv16.php},arxiv={1605.08068},dataset={https://github.com/ashafaei/ubc3v},dataset_name={UBC3V},code={https://github.com/ashafaei/dense-depth-body-parts},image={papers/crv16_1.png},notes={Oral Presentation},bibtex_show={true}}
2015
Shafaei, A. (2015). Multiview Depth-based Pose Estimation. M.Sc. Thesis, University of British Columbia.
Commonly used human motion capture systems require intrusive attachment of markers that are visually tracked with multiple cameras. In this work we present an efficient and inexpensive solution to markerless motion capture using only a few Kinect sensors. We use our system to design a smart home platform with a network of Kinects that are installed inside the house. Our first contribution is a multiview pose estimation system. Unlike the previous work on 3d pose estimation using a single depth camera, we relax constraints on the camera location and do not assume a co-operative user. We apply recent image segmentation techniques with convolutional neural networks to depth images and use curriculum learning to train our system on purely synthetic data. Our method accurately localizes body parts without requiring an explicit shape model. The body joint locations are then recovered by combining evidence from multiple views in real-time. Our second contribution is a dataset of 6 million synthetic depth frames for pose estimation from multiple cameras with varying levels of complexity to make curriculum learning possible. We show the efficacy and applicability of our data generation process through various evaluations. Our final system exceeds the state-of-the-art results on multiview pose estimation on the Berkeley MHAD dataset. Our third contribution is a scalable software platform to coordinate Kinect devices in real-time over a network. We use various compression techniques and develop software services that allow communication with multiple Kinects through TCP/IP. The flexibility of our system allows real-time orchestration of up to 10 Kinect devices over Ethernet.
@thesis{Shafaei2015,author={Shafaei, Alireza},title={Multiview Depth-based Pose Estimation},school={M.Sc. Thesis, University of British Columbia},year={2015},pdf={https://open.library.ubc.ca/media/download/pdf/24/1.0223065/4/1582},image={papers/msc.png},bibtex_show={true}}
2014
Unlabelled 3D Motion Examples Improve Cross-View Action Recognition
We demonstrate a novel strategy for unsupervised cross-view action recognition using multi-view feature synthesis.
We do not rely on cross-view video annotations to transfer knowledge across views, but use local features generated using motion capturedata to learn the feature transformation.
Motion capture data allows us to build a feature level correspondence between two synthesized views.
We learn a feature mapping scheme for each view change by making a naive assumption that all features transform independently.
This assumption along with the exact feature correspondences dramatically simplifies learning.
With this learned mapping we are able to “hallucinate” action descriptors corresponding to different viewpoints.
This simple approach effectively models the transformation of BoW based action descriptors under viewpoint change and outperforms the state of the art on the INRIA IXMAS dataset.
@inproceedings{Guptaetal14,author={Gupta, Ankur and Shafaei, Alireza and Little, James J. and Woodham, Robert J.},title={Unlabelled 3D Motion Examples Improve Cross-View Action Recognition},booktitle={BMVC},year={2014},publisher={BMVA Press},url={http://cs.ubc.ca/research/motion-view-translation/},image={papers/bmvc14_3.jpg},poster={poster/bmvc14_poster.pdf},code={https://github.com/ashafaei/bow-translation},pdf={http://www.bmva.org/bmvc/2014/files/paper017.pdf},bibtex_show={true}}



 Real-Time Human Motion Capture with Multiple Depth Cameras
Real-Time Human Motion Capture with Multiple Depth Cameras

